ניתן לחלק את עולם המודלים הסטטיסטיים לשני סוגים, המובחנים ביניהם בדרך שבה בונים אותם:
מודלים מונחים (Supervised learning)
מודלים לא מונחים (Unsupervised learning)
מודלים מונחים הינם מודלים שנבנים תוך שימוש במשתנה תלוי (כפי שראינו בפרק הקודם של רגרסיה לינארית), ולעומת זאת, מודלים לא מונחים הינם מודלים שבהם אין משתנה תלוי (נניח לדוגמה כשרוצים לחלק את מרחב התצפיות לאשכולות שונים).
בפרק זה נתמקד במידול מונחה, מנקודת מבט מעשית, תוך שימוש בחבילות במשפחה של tidymodels.
קריאה נוספת לצורך העמקה בתיאוריה
ישנן משפחות רבות של מודלים מונחים, בין המוכרים כלולים גם מודלי שפה (כגון ChatGPT), אך גם מודלים לזיהוי נטישה, זיהוי הונאות, רגרסיות למיניהן, למידה עמוקה, ועוד.
הספר הנוכחי אינו מתמקד בתיאוריה העומדת בבסיס המודלים השונים, אלא מהווה עזר מעשי להפעלת המודלים. אתם מוזמנים לעיין בספרים הבאים לצורך העמקה תיאורתית:
כפי שציינו במבוא לספר זה, תהליך ניתוח הנתונים כולל טרנספורמציה על משתנים, וויז’ואליזציות של המשתנים והקשרים שלהם, ומידול. שלב המידול עצמו כולל מספר תתי-שלבים:
חלוקה אקראית של המדגם לקבוצת אימון (training set), קבוצת ולידציה (validation set) וקבוצת מבחן (test set).
בניית מתכון (recipe) להכנת הדאטה למודל. בניית המתכון משמשת להגדרת כל הטרנספורמציות הדרושות לביצוע על הדאטה, לפני שהוא נכנס למודל.
הגדרת מודל/ים: בשלב זה מגדירים את המודלים בהם הולכים לעשות שימוש. גם מבחינת האלגוריתם של המודל (סוג המודל) וגם מבחינת מטרת המודל (רגרסיה לעומת סיווג).
הגדרת תהליך אימון המודל (workflow) ובניית המודל הראשוני (fitting).
כיוונון המודל (tuning).
הערכת ביצועי המודל (evaluation).
שימוש במודל לחיזוי תצפיות חדשות (prediction).
בשלב 1 אנחנו מפרקים את הנתונים לשלוש קבוצות, כאשר מטרת קבוצת האימון הינה לבנות את המודל, מטרת קבוצת הולידציה הינה לכוון את “היפר-פרמטרים” של המודל (hyper-paramters)ומטרת קבוצת המבחן היא לבחון את שגיאת המודל (על דאטה שהמודל לא תלוי בו משום שלא נלמד על בסיסו). קבוצת האימון תשתמש אותנו בשלבים 2-5, קבוצת הולידציה תשמש אותנו בשלב 6, וקבוצת המבחן תשמש אותנו בשלב 7 בלבד. שלבים 2-6 עשויים לחזור על עצמם מספר פעמים במהלך פיתוח מודלים (עם גרסאות שונות למודל או מודלים שונים לגמרי). השלב האחרון הינו השלב שבו אנחנו מפיקים ערך מהמודל, ומשתמשים בו לחיזוי עבור תצפיות חדשות.
כעת נפרק כל אחד מהשלבים ונסביר עליו בפירוט. על מנת להדגים את השלבים נשתמש בדאטה שמלווה אותנו מתחילת הספר (Palmer penguins), כאשר הבעיה שנפתור בפרק זה היא סיווג של תצפית של פינגויין לזכר או נקבה לפי כל המשתנים האחרים שעומדים לרשותנו.
8.3 חלוקת המדגם
ראשית נחלק את המדגם לשלוש הקבוצות: אימון, ולידציה, ומבחן.
אנחנו קוראים את החבילות הנדרשות, מגדירים Seed, כך שנוכל להגריל חלוקה אקראית אך עקבית (תמיד כשנריץ את הקוד נקבל את אותה החלוקה האקראית), ונפצל את הדאטה לשלושת הקבוצות.
library(tidymodels) # reading the meta-package tidymodelslibrary(palmerpenguins) # reading the palmer penguins data set which include penguinstheme_set(theme_bw())set.seed(42) # set an initial seed# Modify the dependent var to a dummypenguins_new <- penguins %>%mutate(sex =factor(sex)) %>%filter(!is.na(sex))# Create the splitpenguin_split <-initial_validation_split(penguins_new, prop =c(0.6, 0.2), strata = sex)penguin_split
ראשית לפני התחלה, שינינו את המשתנה sex למשתנה פקטור. שינוי זה יקל עלינו בהמשך בהפעלת מודלים לסיווג. משתנים קטגוריאליים אחרים המהווים משתנים בלתי-תלויים (משתנים מסבירים) יטופלו בהמשך.
כפי שניתן לראות, המדגם חולק לקבוצת אימון בגודל של 205 תצפיות (המהווה כ-60% מהדאטה המקורי), קבוצת ולידציה בגודל 69 תצפיות (המהווה כ-20% מהדאטה המקורי), וקבוצת מבחן בגודל 70 תצפיות (המהווה כ-20%). גודל הקבוצות הוגדר באמצעות שימוש בארגומנט prop. מקובל לקבוע את קבוצת האימון כקבוצה הגדולה ביותר. ערכים מקובלים לקבוצת האימון והולידציה הם בדרך כלל 70-80% במצטבר, כאשר גודל קבוצת המבחן יהווה כ-20-30% מהדאטה בהתאמה. עם זאת, אין הגדרות חד-משמעיות בהיבט זה, וניתן לחרוג ממספרים אלו כתלות בצורך.
השתמשנו בארגומנט strata על מנת לבצע את הדגימה באופן ששומר על הפרופורציות של מין התצפיות בתוך כל תת-קבוצה. ארגומנט זה שימושי במיוחד כאשר הקבוצות אינן מאוזנות (קבוצה מסוימת קטנה משמעותית מאחרות).
על מנת לחלץ את הדאטאות עצמם של כל אחת מהקבוצות נשתמש בפונקציות הבאות:
את המשך הלמידה על הדאטה, כולל בניית המודל, נבצע על קבוצת האימון בלבד penguin_train.
תרגיל: הבנת הדאטה לפני צלילה למודל
בדרך כלל לאחר פיצול הדאטה נבצע ויז’ואליזציות שונות כדי להבין איך משתנים שונים משפיעים על המשתנה התלוי (לפני שרואים את השפעתם במודל עצמו). בשלב זה העבודה שתוארה בפרק 4 תהא משמעותית מאוד. לצורך תרגול, בחנו כיצד המשתנים השונים שבדאטה שלנו (penguin_train) משפיעים על מין התצפית.
השתמשו בויז’ואליזציות שונות כפי שנלמדו והודגמו בפרק על ויז’ואליזציות. לאור הבדיקה, אילו משתנים הייתם מצפים שיהיו משמעותיים במודלים שנפתח?
ישנן שלוש תצפיות בעלות ערך חסר (ללא מין) בקבוצת האימון. לא נוכל להשתמש בתצפיות אלו לצורך אימון המודל - הסבירו מדוע.
8.4 בניית מתכון
כפי שמיד תראו, חבילת tidymodels מאמצת ז’רגון של מטבח כמו בניית מתכון - recipe, סחיטת מיצים - juice, אפייה - bake, גזר לבן - parsnip, ועוד.
בשלב זה נבנה “מתכון” שהמטרה שלו להגדיר את השינויים שעובר הדאטה לפני שהוא נכנס למודל. במובן מסויים, התהליך מאוד דומה לתהליך שתואר בפרק 3 על הכנת נתונים, אך יש הבדל מהותי: מתכון זה יופעל אוטומטית בכל פעם שנרצה להפעיל את המודל מחדש על תצפיות חדשות, וכן הוא יופעל גם במהלך שלב הכיוונים (וגם ניתן יהיה להגדיר היפר-פרמטרים כחלק מהמתכון, ולאפשר לשלב הכיוונון לבדוק גם אותם).
בבניית המתכון הבא נפעיל מספר צעדים, החל מהפקודה recipe לאתחול המקום ודרך צעדים שונים (step) שמיד נסביר אותם.
# Excuse the pun (for the name...)penguin_recipe <-recipe(sex ~ ., data = penguin_train) %>%step_naomit(bill_length_mm:body_mass_g) %>%step_normalize(all_numeric_predictors()) %>%step_dummy(species, island) %>%step_rm(year) %>%step_corr(bill_length_mm:body_mass_g)penguin_recipe
• Removing rows with NA values in: bill_length_mm:body_mass_g
• Centering and scaling for: all_numeric_predictors()
• Dummy variables from: species and island
• Variables removed: year
• Correlation filter on: bill_length_mm:body_mass_g
במתכון שלעיל הגדרנו ארבעה צעדים (פונקציות שמתחילות ב-step_*).
בצעד הראשון אנחנו משמיטים ערכים חסרים מהדאטה באמצעות step_na_omit. בדאטה שלנו תצפיות בעלות ערך חסר מכילות ערך חסר בכל המשתנים הרלוונטיים, ולכן בחרנו להשמיט אותן לגמרי. באופן כללי, בבעיות אחרות כדאי לנסות לזקוף ערכים חסרים על ידי שימוש בצעדים כגון step_impute_bag, step_impute_knn, step_impute_linear, ועוד לפני שמסירים את התצפיות לגמרי. ביצוע צעד של זקיפת נתונים יאפשר להתמודד עם חיזוי של תצפיות חדשות גם אם הן מגיעות עם ערך חסר, בעוד שצעד הסרה ימנע מאיתנו לספק תחזית.
הצעד הבא, step_normalize, הופך את כל המשתנים המספריים (all_nominal_predictors()) למשתנים מנורמלים (כלומר בעלי תוחלת 0 וסטיית תקן 1). צעד זה גם ישמור את התוחלת וסטיית התקן המחושבת על קבוצת האימון, וישתמש בהן לנרמול של תצפיות חדשות בשלב החיזוי (חשבו למה).
הצעד הבא, step_dummy,הופך משתנים מסוג מחרוזת או פקטור למשתני דמי (בעלי ערכי 0 או 1). במקרה שלנו אלו משתני סוג הפינגויין, האי שבו נמדדה התצפית, ומין הפינגויין (שכבר הומר למשתנה פקטור בתחילת הקוד לפני הפיצול הראשוני לקבוצות). ניתן לשים לב שהמשתנה אי התצפית פוצל לשני משתני דמי (במקור ישנן שלוש רמות Dream, Torgersen, ו-Biscoe, כאשר השניים הראשונים הם 0 המשמעות היא שהתצפית הגיעה מהשלישי), וכך גם המשתנה של סוג הפינגויין (שפוצל לשני משתני דמי Chinstrap, Gentoo, והשלישי Adelie אינו בדאטה ומשתמע מהשניים האחרים).
הצעד step_rmמוריד את משתנה השנה (שמתעד מתי נמדדה התצפית). הנחת העבודה בהסרת המשתנה היא שהשנה שבה נמדדה התצפית ומין הפינגויינים אינם קשורים סטטיסטית (בהנחה שהתפלגות מין הפינגויינים נשארת קבועה בין השנים). הפעלת הפוקנציה מאוד דומה לפונקציה select שבה דנו בפרק הכנת הנתונים (ואכן קיימת גם פונקצית step_select רק שהפעלת step_select(-year) היתה גורמת לבעיות בהמשך הרצת הקוד).
הצעד האחרון שבחרנו לבצע הינו step_corr. צעד זה בוחן קורלציות בין המשתנים ובמידה והוא מזהה משתנה שבעל קורלציות גבוהות למשתנים אחרים, הוא מסיר אותו (במקרה זה לצעד זה אין השפעה, ואף משתנה אינו מוסר משום שאין מולטיקולינאריות, כפי שמיד נראה).
נציין שרשימת הצעדים האפשריים גדולה במיוחד ומבוססת על best practices של הנדסת נתונים (כפי שנקראים בעגה המקצועית - feature engineering). מומלץ להיעזר ברשימת הצעדים המתעדכנת באתר הרשמי. כמו כן, תמיד ניתן להגדיר צעדים חדשים נוספים, לדוגמה על ידי שימוש ב-step_mutate להגדרת משתנה נוסף שהוא תוצאת חישוב של משתנים אחרים, או באופן מתקדם יותר על ידי פיתוח של פונקציה חדשה.
על מנת לבחון את תוצאת המתכון, ניתן להשתמש בפונקציות הכנה ואפייה, באופן הבא:
באמצעות הפונקציה prep אנחנו מנחים את הפעלת הצעדים על בסיס קבוצת האימון, והפונקציה bake מריצה אותם בפועל. אולי זה נראה ככפילות מסוימת אבל בעצם יכלנו להריץ את bake על כל דאטה (כגון קבוצת הולידציה, קבוצת המבחן, או תצפיות חדשות לגמרי). אם מפעילים את bake עם new_data = NULL אז היא פשוט תפעיל הכל על קבוצת האימון.
8.5 הגדרת המודל
הבעיה עמה אנחנו מתמודדים בפרק זה היא בעיית סיווג (classification), בהתאם לכך, ישנם מודלי סיווג שבאפשרותנו להשתמש בהם, כגון: רגרסיה לוגיסטית, עצי החלטה, יערות אקראיים, boosting, bagging, ועוד. כפי שציינו ניתן להתעמק במודלים השונים, בשני הספרים שצויינו בתחילת הפרק.
נדגים הגדרה של שלושה מודלים שונים: רגרסיה לוגיסטית, יער אקראי, ו-boosting.
עד כה כל הפעולות שעשינו היו זהות לכל המודלים (פיצול והכנת הדאטה), וזו הפעולה הראשונה שבה אנחנו מבחינים בין שלושה מודלים שונים. שלושת המודלים יקבלו את אותו הדאטה בשלב האימון. העוצמה הגדולה של tidymodels היא ביכולת שלה לאפשר לנו ממשק לחבילות מרובות (כפי שמיד נסביר, אנחנו מפעילים פה פונקציות מחבילות stats, ranger, ו-xgboost), תוך שימוש בשפה אחידה. במקור, לכל חבילה שבה אנחנו משתמשים בהגדרה לעיל יש ממשק שונה שצריך ללמוד אותו אם מפעילים ישירות את החבילות, אבל במקרה זה tidymodels מספקת לנו מעטפת אחידה.
כל מודל מוגדר עם ארגומנט mode שמבחין בין בעיות סיווג לבעיות רגרסיה. במקרה זה אנחנו עובדים עם בעיית סיווג, ולכן הארגומנט הוגדר כ-mode = classification.
בחבילת parsnip שהינה חבילה בתוך tidymodels ישנם ממשקים שונים להפעלת פונקציות מידול שונות, ובמקרה זה השתמשנו בשלושה ממשקים:
הפונקציה logistic_reg שבאמצעות engine = "glm" הנחנו אותה לעבוד עם פונקציית glm (generalized linear models) שנמצאת בחבילת הבסיס stats. מעיון בתיעוד של logistic_reg תוכלו לראות שהיא מספקת ממשקים למעל עשר חבילות שונות של רגרסיה לוגיסטית (הכללות שונות של המודל הבסיסי או אלגוריתמים בעלי יעילות טובה יותר).
הפונקציה rand_forest גם היא מספקת ממשקים לפוקנציות ואלגוריתמים שונים של יערות אקראיים, ובמקרה זה הנחנו את הפונקציה להוות ממשק לחבילת ranger.
הפונקציה boost_tree שמייצרת מודלים המורכבים מהרבה תתי מודלים אחרים (ensemble), ובמקרה זה תעבוד כממשק לחבילת xgboost.
כל פונקציית ממשק כזו תפעיל פונקציות מחבילות אחרות (בדוגמה שלנו מחבילת stats, ranger, ו-xgboost), ולכן עלינו לוודא שהתקנו את החבילות הנדרשות.
פונקציות הממשק יודעות להעביר ארגומנטים שונים שרלוונטיים לפונקציות שהן מפעילות. לדוגמה לחבילת ranger אנחנו מעבירים את הארגומנט mtry = 3 שמסביר מכמה משתנים יש לבנות כל עץ שמשתתף ביער שלנו. עיון בתיעוד הפונקציות בחבילות של האלגוריתמים יראה אילו ארגומנטים קיימים.
8.6 הגדרת תהליך ומודל ראשוני
כעת, על מנת להפעיל את האלגוריתמים השונים לצורך בניית המודלים, נגדיר תהליך בניה ונבנה את המודל בפועל באופן הבא:
לפעמים מודל הוא “קופסה שחורה” ולא ניתן להתעמק בו (לדוגמה, מודלי למידה עמוקה, ובפרט מודלי שפה כגון ChatGPT הם קופסה שחורה, בהיבט שקשה לחקור את המודל אך קל לחזות בתוצאותיו).
עם זאת, לעיתים ההתעמקות בתכונות של מודל יכולה לשפוך אור על הקשר שבין המשתנים (כפי שראינו בפרק 7. לשם כך עומדות לרשותנו פונקציות שונות המאפשרות לחלץ את המודל וללמוד את תכונותיו. נדגים חקירה של מודל הרגרסיה הלוגיסטית ושל מודל ה-Boosting.
Call:
stats::glm(formula = ..y ~ ., family = stats::binomial, data = data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.5568 1.7199 2.650 0.008060 **
bill_length_mm 3.2490 0.9362 3.471 0.000519 ***
bill_depth_mm 3.4483 0.8763 3.935 8.32e-05 ***
flipper_length_mm 0.3471 0.8711 0.398 0.690263
body_mass_g 4.5377 1.1314 4.011 6.06e-05 ***
species_Chinstrap -6.9794 2.1344 -3.270 0.001076 **
species_Gentoo -7.6559 3.2386 -2.364 0.018081 *
island_Dream 0.1637 1.1350 0.144 0.885352
island_Torgersen -0.6082 1.2098 -0.503 0.615163
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 275.868 on 198 degrees of freedom
Residual deviance: 76.684 on 190 degrees of freedom
AIC: 94.684
Number of Fisher Scoring iterations: 7
הפלט דומה לפלט הפקודה summary כאשר מריצים אותה על מודל הרגרסיה הלינארית שראינו בפרק הקודם אך עם מספר הבדלים, לדוגמה:
במקום Residuals אנחנו רואים Deviance Residuals (חישוב שונה של שאריות המבוסס על פונקציית נראות במקום הפרש בין ערך התצפית בפועל לערך החזוי של התצפית).
במקום מבחן \(F\) וערך של \(R^2\) אנחנו רואים ערך של AIC (Akaike Information Criteria) - קריטריון אחר המאפשר להשוות בין מודלים.
משמעות המקדמים שונה (Estimate): ברגרסיה לוגיסטית, האקספוננט של המקדם הוא ה-Odds Ratio, כלומר פי כמה שינוי של יחידה במשתנה המסביר מעלה את הסבירות לשינוי הסיווג.
נציג את ערכי האקספוננט של המקדמים. נשתמש בפונקציה tbl_regression מחבילת gtsummary, עם הארגומנט exponentiate = TRUE על מנת להציג את האקספוננט של המקדמים במקום המקדמים עצמם.
לדוגמה, עיון במקדם של אורך המקור (bill_length_mm) שערכו כ-3.62 (בטבלת הפלט הגולמית), מעיד על כך ששינוי של 1מ”מ באורך המקור, מעלה את ה-Odds Ratio (היחס בין הסבירות להשתייך לקבוצת הזכרים לסבירות להשתייך לקבוצת הנקבות) פי 37 (עמודת OR בטבלת הפלט המעובדת). ממצא זה מובהק סטטיסטית (p-value<0.001).
המשתנה המשמעותי ביותר כפי שעולה מתוצאות מודל הרגרסיה הלוגיסטית הינו עומק המקור (bill_depth_mm) עם ערך Odds Ratio של 183.
תרגיל: אינטראקציות ברגרסיה לוגיסטית
בפרק הקודם שדן ברגרסיה לינארית הדגמנו כיצד פועלות אינטראקציות ברגרסיה לינארית. כמו כן, ראינו שישנם קשרים בין הזנים השונים של הפינגויינים לבין תכונותיהם, וכעת ראינו גם שיש קשר בין מין הפינגויינים לתכונותיהם.
העריכו כיצד הממצאים הללו עשויים להשפיע על ביצועי מודל הרגרסיה הלוגיסטית שהוצג?
אילו אינטראקציות הייתם שוקלים להוסיף למודל על מנת לשפרו?
הוסיפו את האינטראקציות הללו על ידי שימוש בפקודה step_interact במתכון שהוצג, והריצו מחדש את מודל הרגרסיה הלוגיסטית.
נתחו את תוצאות המודל שקיבלתם לאחר האינטראקציה, מה אתם מסיקים מהמודל החדש?
מומלץ להעמיק בתכונות הרגרסיה הלוגיסטית, לדוגמה בספר של Hastie, Tibshirani, and Friedman (2009).
נדגים כעת כיצד אנו מחלצים את מודל ה-boosting ולומדים ממנו על השפעת המשתנים על מין הפינגויין.
בשונה ממודל הרגרסיה הלוגיסטית, למודל boosting אין “מקדמים” במובן של מקדמים של מודל רגרסיה לוגיסטית. עם זאת, ניתן להשתמש בו כדי לחלץ את חשיבות המשתנים השונים, קרי, דירוג של המשתנים על פי מידת ההשפעה שיש להם על רמת הדיוק של העצים של המודל (תתי-המודלים מהם מורכב מודל ה-boosting). חילוץ נתונים אלו דורש היכרות והפעלה של פקודות מחבילת xgboost. במקרה זה אנחנו מציגים את ה-Gain של המשתנים השונים, כלומר התרומה היחסית שלהם בבעיית הסיווג (אחוזים גבוהים יותר משמעם תרומה גבוהה יותר למודל החיזוי).
importance_matrix <- xgboost::xgb.importance(model = bst_model_extract)importance_matrix %>%mutate(Feature = forcats::fct_reorder(Feature, Gain)) %>%ggplot(aes(y = Feature, x = Gain)) +geom_col() +ggtitle("Feature Gain in the Penguin Sex Boosting Model") +theme_bw()
כעת נעבור לשלב כיוונון המודלים, ונלמד מהם היפר-פרמטרים (Hyper parameters).
8.7 כיוונון מודלים
ככל שעולה מידת המורכבות של מודלים, כך מתווספים להם פרמטרים הנקראים “היפר-פרמטרים” (Hyper parameters). יש הבדל מהותי בין המונח “פרמטר” (המתייחס לערך של האוכלוסיה שאנחנו אומדים, כגון תוחלת או סטיית תקן), לבין היפר-פרמטר. כאשר המונח היפר-פרמטר מתייחס לפרמטרים של האלגוריתם (ולא של האוכלוסיה). להלן מספר דוגמאות להיפר-פרמטרים:
מספר העצים שישתתפו במודל (נניח מסוג יערות אקראיים או מסוג boosting).
מספר האיטרציות המירבי שאלגוריתם צריך לעשות במהלך אימון המודל.
מספר הפיצ’רים המירבי שמורשים להשתתף בכל עץ במודל יערות אקראיים.
עומק העץ המירבי במודל יערות אקראיים.
לעיתים, ההיפר-פרמטר יהיה תוצר של צעדי המתכון שהכנו. לדוגמה אם השתמשנו בדיסקרטיזציה (step_discretize הפיכה של משתנה רציף למשתנה בדיד בעל מספר ערכים מוגבל), אז מספר הערכים שאנחנו מגדירים למשתנה הבדיד הינו היפר-פרמטר (הארגומנט num_breaks בדוגמה). ערכים שונים שלו עשויים להניב מודלים בעלי ביצועים שונים (מעט מדי ערכים יפגעו ביכולת של המשתנה להסביר את המשתנה התלוי, ויותר מדי ערכים יכניסו למודל הרבה פיצ’רים שיביאו לתופעה של התאמת-יתר over-fitting, גם היא תניב מודל בעל ביצועיים נחותים).
על כן, מהסיבות הללו ועוד, נשאלת השאלה- איך נכוון (tune) את המודל שלנו, על מנת שנצליח לבחור בסט הערכים המיטבי (שיביא את ביצועי המודל הטובים ביותר). מדובר בבעיה מורכבת שכן ברגע שיש לנו שילוב של היפר-פרמטרים, ישנם הרבה אפשרויות לבחינה (לדוגמה, חמישה פרמטרים שלכל אחד חמישה ערכים אפשריים מהווים \(5^5\) צירופים שונים.
נדגים כעת כיצד אנחנו מכווננים את מודל היער האקראי בהתייחס להיפר-פרמטרים mtry, trees, n_min המתארים את מספר המשתנים המסבירים שמופיעים בכל עץ, מספר העצים הכללי במודל, וגודל המדגם המינימלי לכל קודקוד בעץ (שמתחתיו לא ניתן לפצל את הקוקוד).
כיוונון המודל מתבצע על ה-Validation set, ולבסוף כאשר נמצא את סט ערכי ההיפר פרמטרים המיטבי, נבצע אימון מחודש בהתאם לסט הערכים המיטבי, על גבי ה-Train set, ונאמוד את השגיאה באמצעות ה-Test set.
הפקודה הבאה מגדירה מודל, שבו רכיבים מסוימים הינם רכיבים אשר יעברו כוונון. הפונקציה tune() משמשת כמעין “ממלא מקום”. הפונקציות בהן נשתמש בהמשך ידעו להחליף את tune() בערכים שונים במסגרת החיפוש המתבצע בתהליך הכיוונון.
# Random forest - tunning# We'r tunning on the following hyper-parameters (mtry, trees, min_n)penguin_forest_tune_spec <-rand_forest(mode ="classification",engine ="ranger",mtry =tune(),trees =tune(),min_n =tune())penguin_forest_tune_spec
Random Forest Model Specification (classification)
Main Arguments:
mtry = tune()
trees = tune()
min_n = tune()
Computational engine: ranger
כעת נגדיר את רשת החיפוש (Search grid). המונח רשת מבטא את העובדה שישנם מספר היפר-פרמטרים וההצלבה ביניהם מייצרת מעין “רשת” שבה מתבצע החיפוש.
לחלק מהפונקציות בהם השתמשנו (trees, min_n) יש ערכי ברירת מחדל המגדירים את טווח החיפוש.
עבור mtry הגדרנו את טווח החיפוש. הארגומנט levels מגדיר עבור כמה ערכים בטווח זה יבוצע החיפוש. כלומר, ברשת שהגדרנו יבוצע חיפוש ברשת של \(3^3=27\) נקודות (כל ההצלבות האפשריות בין ההיפר-פרמטרים).
הפקודה הבאה תחלק את קבוצת ה-validation ל-v=5 קבוצות באקראי. על כל אחת מקבוצות אלו יבנו 27 מודלים (כלומר בסך הכל 135 מודלים יבנו).
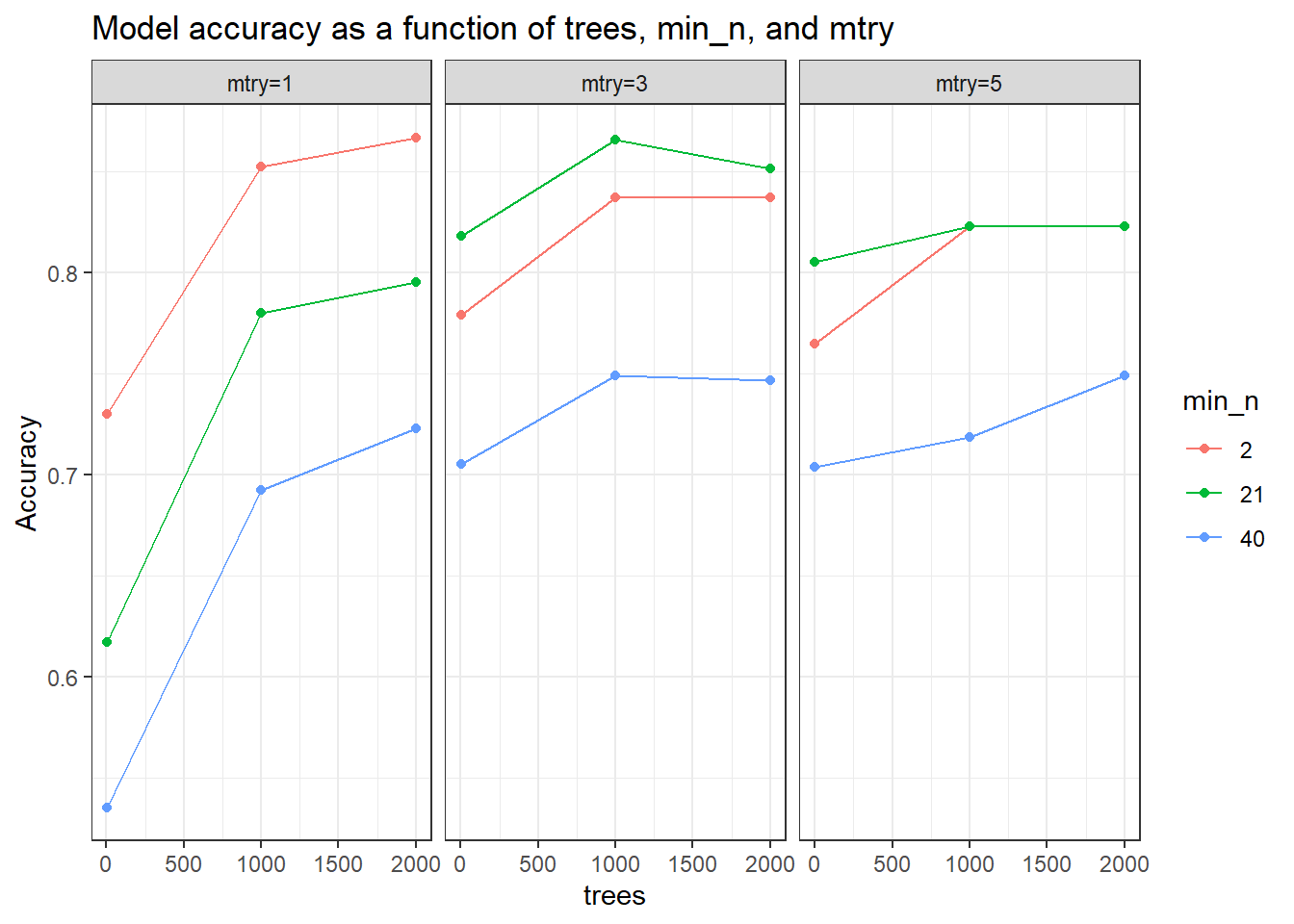
penguin_forest_metrics %>%filter(.metric =="accuracy") %>%ggplot(aes(x = trees, y = mean, color = min_n)) +geom_line() +geom_point() +facet_wrap(~ mtry) +theme_bw() +ylab("Accuracy") +ggtitle("Model accuracy as a function of trees, min_n, and mtry")
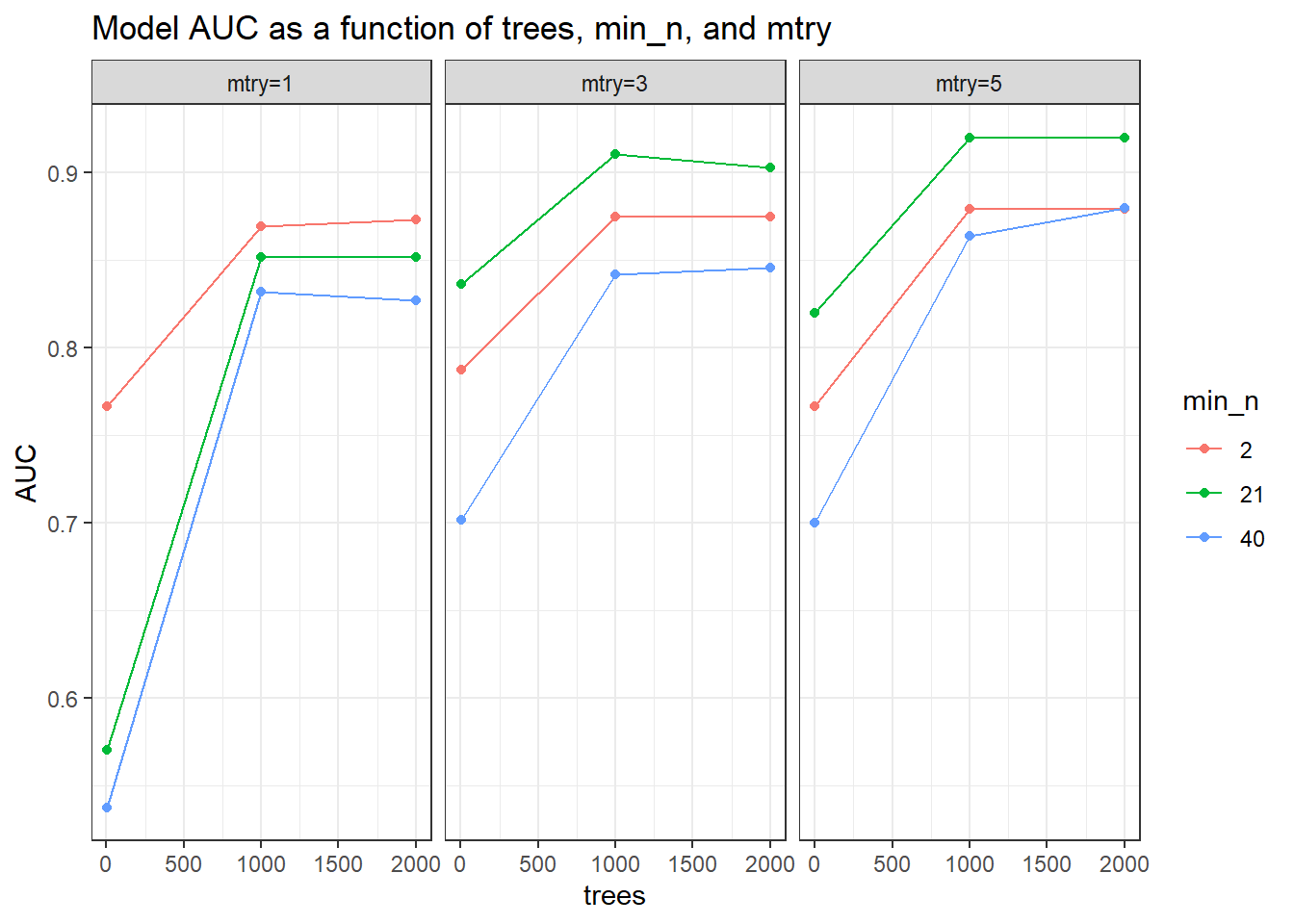
penguin_forest_metrics %>%filter(.metric =="roc_auc") %>%ggplot(aes(x = trees, y = mean, color = min_n)) +geom_line() +geom_point() +facet_wrap(~ mtry) +theme_bw() +ylab("AUC") +ggtitle("Model AUC as a function of trees, min_n, and mtry")
# A tibble: 1 × 4
mtry trees min_n .config
<int> <int> <int> <chr>
1 5 1000 21 Preprocessor1_Model15
בחלק הבא של פרק זה, נסביר מהם מדדי הדיוק (מה המשמעות של Accuracy, ROC, AUC, ועוד), בינתיים נבחין בכך שמניתוח שני התרשימים, נראה שהדיוק הגבוה ביותר במונחי accuracy מתקבל בעבור סט הערכים:
min_n= 21
mtry=5
trees=2000
במונחי AUC_ROC הדיוק הגבוה ביותר מתקבל כאשר מספר העצים הוא 1000 וערך min_n הינו 2, אך ביצועים אלו דומים גם לביצועים בעבור סט הערכים לעיל, ולכן יש העדפה קלה לבחירתו.
ייתכן שאם היינו מגדילים את מספר העצים במודל היתה מתקבלת רמת דיוק גבוהה אף יותר (משום שנראה שיש מגמת עליה קלה ברמת הדיוק כאשר מספר העצים גדל).
כעת נסביר מה משמעות מדדי הדיוק השונים, נאמן את המודל הסופי שלנו, ונעריך את ביצועיו.
8.8 הערכת ביצועי המודל
במהלך החלק הקודם הזכרנו כמה מדדים המשמשים להערכת ביצועים של מודלי סיווג: Accuracy, ROC, AUC, וישנם מדדים נוספים כגון רגישות (Sensitivity), סגוליות (Specificity). מילה נרדפת נוספת לרגישות הינה Recall.
8.8.1 רגישות וסגוליות
רגישות היא ההסתברות לזהות הישנות תכונה מסוימת מתוך כלל מקרי ההישנות של התכונה. סגוליות הינה ההסתברות לזהות את אי-ההישנות של התכונה מתוך כלל המקרים בהם התכונה אינה מתקיימת.
נקפוץ רגע מהדוגמה של הפינגויינים עמם עבדנו עד כה ונדגים את המונחים רגישות וסגוליות באמצעות היכולת לזהות לקוחות פוטנציאליים לעדשות מגע. בתרשים הבא יש אוכלוסיה של אנשים: חלקם עונדים משקפים אופטיים, חלקם משקפי שמש, וחלקם ללא משקפים. נניח שלקוחות פוטנציאליים הינם כל האנשים אשר עונדים משקפיים אופטיים (אבל לא משקפי שמש).
נניח שפיתחנו מודל סטטיסטי אשר סיווג את כל האנשים שיש עליהם חצים מעוגלים כלקוחות פוטנציאליים לעדשות מגע.
הרגישות שלנו היא מספר החצים הכחולים (אנשים שהמודל זיהה שעונדים משקפים אופטים ולכן הם אכן לקוחות פוטנציאליים) חלקי סך האנשים אשר עונדים משקפיים אופטיים (יש אחד שאין עליו חץ כחול- מספר 8 משמאל בשורה העליונה). לכן, הרגישות שלנו היא 75% (3 מתוך 4).
הסגוליות היא מספר האנשים שסווגו כ-“לא לקוחות” מתוך סך הלקוחות שאינם לקוחות פוטנציאליים. הפספוסים היחידים הינם שני חצים צהובים (אנשים בעלי משקפי שמש לא אופטיים, אשר סווגו כלקוחות בטעות). כלומר, הסגוליות שלנו היא 89% (16 איש מתוך 18 איש).
הדיוק הכללי (Accuracy) הוא מספר הסיווגים הנכונים, בדוגמה הוא 86%: 19 סיווגים נכונים מתוך 22 אנשים באוכלוסיה (86%).
מקובל לארגן את תוצאות המודל במטריצת בלבול, שבדוגמה לעיל תיראה כך:
מטריצת בלבול - מודל המשקפים
מודל סיווג פוטנציאל
מודל סיווג היעדר פוטנציאל
קיים פוטנציאל במציאות
3
1
לא קיים פוטנציאל במציאות
2
16
8.8.2 טעות מסוג ראשון וטעות מסוג שני
מקובל להגדיר טעות מסוג ראשון (type I error) כמקרה שסווג כנכון למרות שאינו נכון, וטעות מסוג שני (type II error) כמקרה שסווג כלא נכון, למרות שהינו נכון.
ניתן להסביר את ההגדרות של סווג כנכון או של סווג כלא נכון, באופן מדויק יותר אם משאילים את המושגים הסטטיסטיים עליהם דנו בפרק 6, כאשר: \[
\operatorname{Type-I\ Error}=Pr\left(\operatorname{Reject }H_0|H_0\right)
\]
\[
\operatorname{Type-II\ Error}=Pr\left(\operatorname{Do Not Reject }H_0|H_1\right)
\]
לשם פשטות נסכם את המונחים לעניין מודלי סיווג במטריצה הבאה:
מטריצת בלבול - סיכום מונחים חשובים
מודל סיווג פוטנציאל
מודל סיווג היעדר פוטנציאל
קיים פוטנציאל במציאות
רגישות
טעות מסוג שני (type-II)
לא קיים פוטנציאל במציאות
טעות מסוג ראשון (type-I)
סגוליות
תרגיל: סווגו את הטעות לסוג ראשון או סוג שני
גבר שסווג בהריון
אשה בהריון אשר בדיקת הריון שלה יצאה שלילית
חולה קורונה אשר סווג כבריא
אדם בריא אשר סווג כחולה בקורונה
לעיתים הקביעה של טעות מסוג ראשון או מסוג שני אינה ברורה ונתונה לפרשנות, כמו לדוגמה, האם סיווג פינגויין ממין זכר כפינגויין ממין נקבה הוא טעות מסוג ראשון או מסוג שני? על מנת להכריע, נדרש להגדיר קודם את “המצב הנומינלי” (המקביל של “השערת האפס”). במקרה שלנו, נגדיר את המצב הנומינלי כזכר (H0), כלומר זיהוי נכון של נקבה ישויך לרגישות המודל, זיהוי נכון של זכר ישוייך לסגוליות המודל.
בהתאם לכך, טעות מסוג ראשון תהא זיהוי של זכר כנקבה, וטעות מסוג שני היא אי-זיהוי של נקבה (וסיווגה כזכר במקום).
כעת אנחנו בשלים לבנות את המודל הסופי שלנו, ולנתח מטריצת הבלבול שלו, וכן להסביר ולהציג את ה-ROC ואת ה-AUC שלו.
8.9 בניית מודל סופי
כפי שראינו, המודל המיטבי על פי הבחינות שביצענו הינו מודל יער, עם היפר-פרמטרים כפי שנמצאו לעיל, להלן בנייתו:
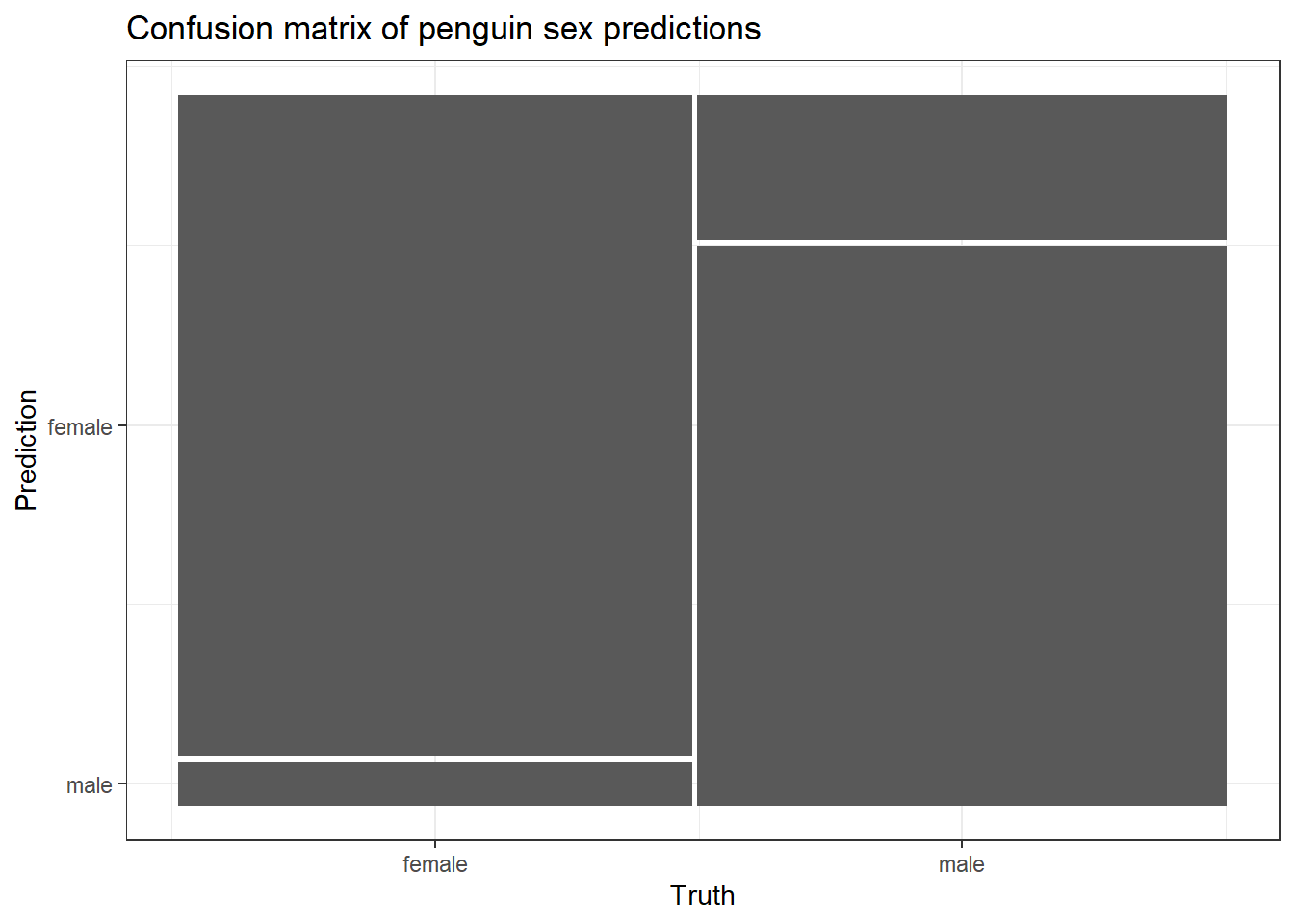
Truth
Prediction female male
female 31 7
male 2 27
autoplot(penguin_conf_mat) +ggtitle("Confusion matrix of penguin sex predictions")
שימו לב לשימוש שעשינו בפונקציה predict אשר משמשת אותנו לחיזוי עבור תצפיות חדשות:
פונקציה זו יכולה להחזיר את ההסתברויות לשיוך התצפיות על ידי שימוש בארגומנט type=prob.
penguin_pred_prob <-predict(penguin_forest_best, new_data = penguin_test, type ="prob")penguin_pred_prob
מרבית המודלים מחזירים הסתברויות כתוצאת החישוב, כאשר מטריצת הבלבול שהצגנו קודם השתמשה בערך ברירת מחדל של 0.5. ניתן לשנות את הרגישות והסגוליות של המודל, על ידי שינוי סף זה. לדוגמה אם נציב סף של 0.25, אז יכולת המודל לזיהוי זכר תגדל, אך גם הטעות של זיהוי זכר בהינתן נקבה.
Truth
Prediction female male
female 21 0
male 12 34
במטריצה הקודמת היו 7 מקרים של זיהוי נקבה למרות שהיו זכרים, וכעת מספר זה ירד ל-0. עם זאת, כעת ישנם 12 מקרים של זיהוי שגוי של זכר (קודם מספר זה היה 3). הרגישות (לזיהוי זכר) עלתה.
מכיוון שסיפים שונים מייצרים מטריצת בלבול שונה, וצמד רגישות-סגוליות שונה, ניתן לאפיין מודל על ידי התחשבות בכלל הסיפים האפשריים תוך שימוש במונחים שהצגנו בשלב מוקדם יותר בפרק (ROC ו-AUC), שכעת נסביר אותם.
8.9.1 הצגת ה-ROC וה-AUC
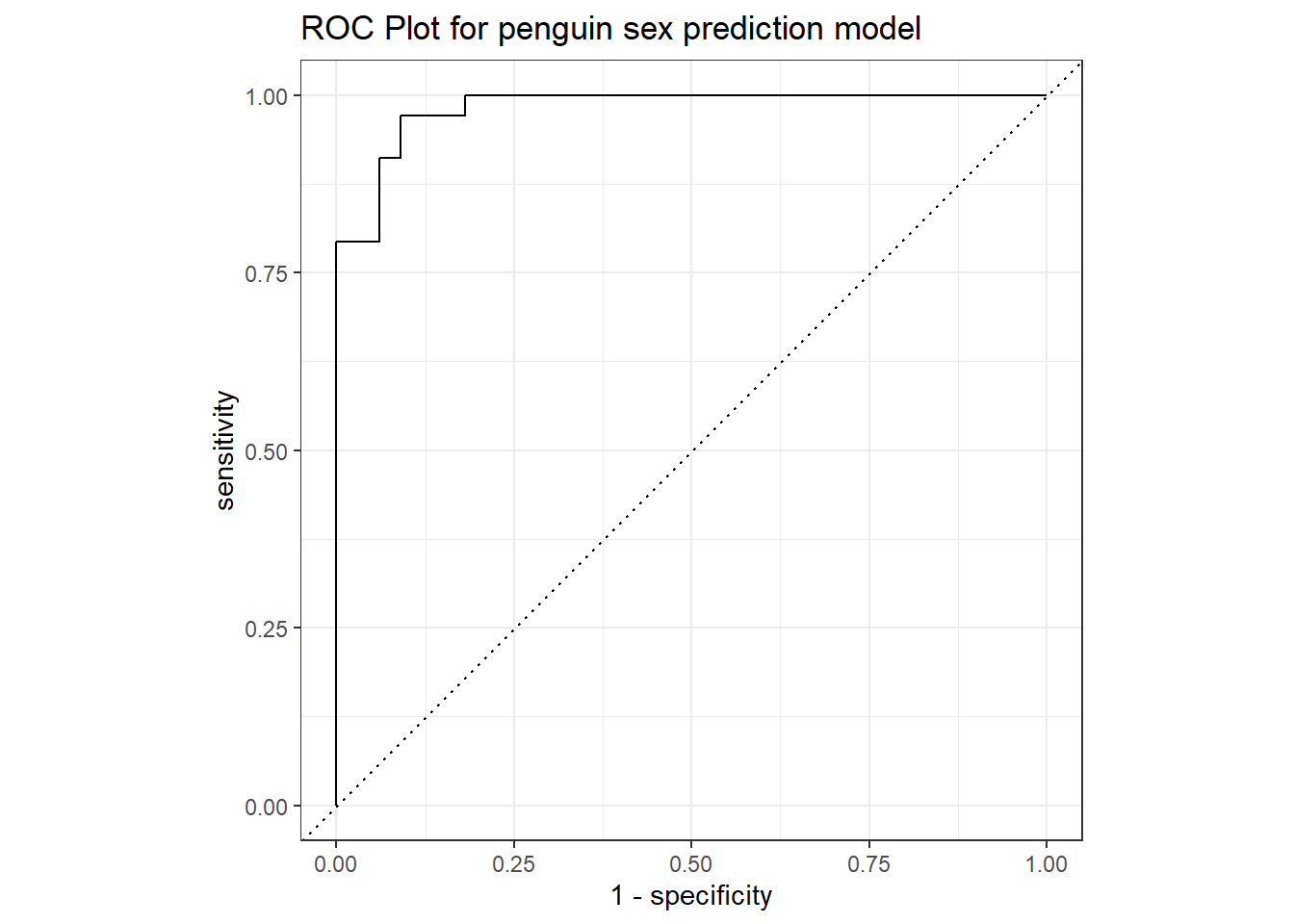
המונח ROC הוא ראשי תיבות של Receiver Operating Characteristic curve, והוא מציג בציר X את השגיאה מסוג ראשון (False-Positive rate), ובציר Y את הרגישות (True-Positive rate).
autoplot(roc_plot) +ggtitle("ROC Plot for penguin sex prediction model")
כל נקודה בתרשים (בקו הרציף העליון) מתייחסת לרף חיזוי מסוים (רף שאם תוצאת מודל החיזוי גבוהה ממנו אז התצפית מסווגת כ”כן” או כפינגויין זכר במקרה שלנו). מכיוון שבקבוצת המבחן שלנו יחסית מעט תצפיות, התרשים מקבל צורה ברורה של תרשים מדרגות.
הקו המקווקו (שחוצה את התרשים באמצע) מהווה “מודל אקראי” (כלומר הקו המקווקו הוא מודל סיווג של הטלת מטבע). ככל שהקו של המודל רחוק מהמודל האקראי כלפי מעלה, כך ביצועי המודל טובים יותר.
אם היינו מאמנים מספר מודלים מסוגים שונים, אז היינו יכולים לשים מספר תרשימים על גרף אחד, וכך להשוות את הביצועים ביניהם.
תרגיל: הבנת תרשים ה-ROC
מה המשמעות של הנקודה (0,1), אם המודל נוגע בה?
מה המשמעות של מודל שעובר מתחת לקו המקווקו? כיצד ניתן לשפר אותו בקלות?
המדד AUC הינו השטח מתחת לעקומת ה-ROC (Area Under the Curve), והוא מדד שמאפשר לנו השוואה בין ביצועי מודלים שונים, בהסתכלות על מספר אחר שמייצג באופן כללי את ביצועי המודל (בעצם, זה בדיוק האופן שבו השתמשנו במדד זה בשלב כיוונון המודלים).
במקרה זה יכולת החיזוי של המודל טובה מאוד. למודל אקראי (של הטלת מטבע) יהיה AUC של 0.5, ומודל מושלם יהיה בעל AUC של 1.
8.9.2 דוגמה להשוואה בין מודלים
נדגים את ההשוואה בין שלושה מודלים: מודל הרגרסיה הלוגיסטית, מודל הבוסטינג, ומודל היער האקראי (לאחר כיוונון). הלולאות שבהן אנו משתמשים בקוד הבא מבוססת על חבילת purrr ומוסברת בפרק הבא.
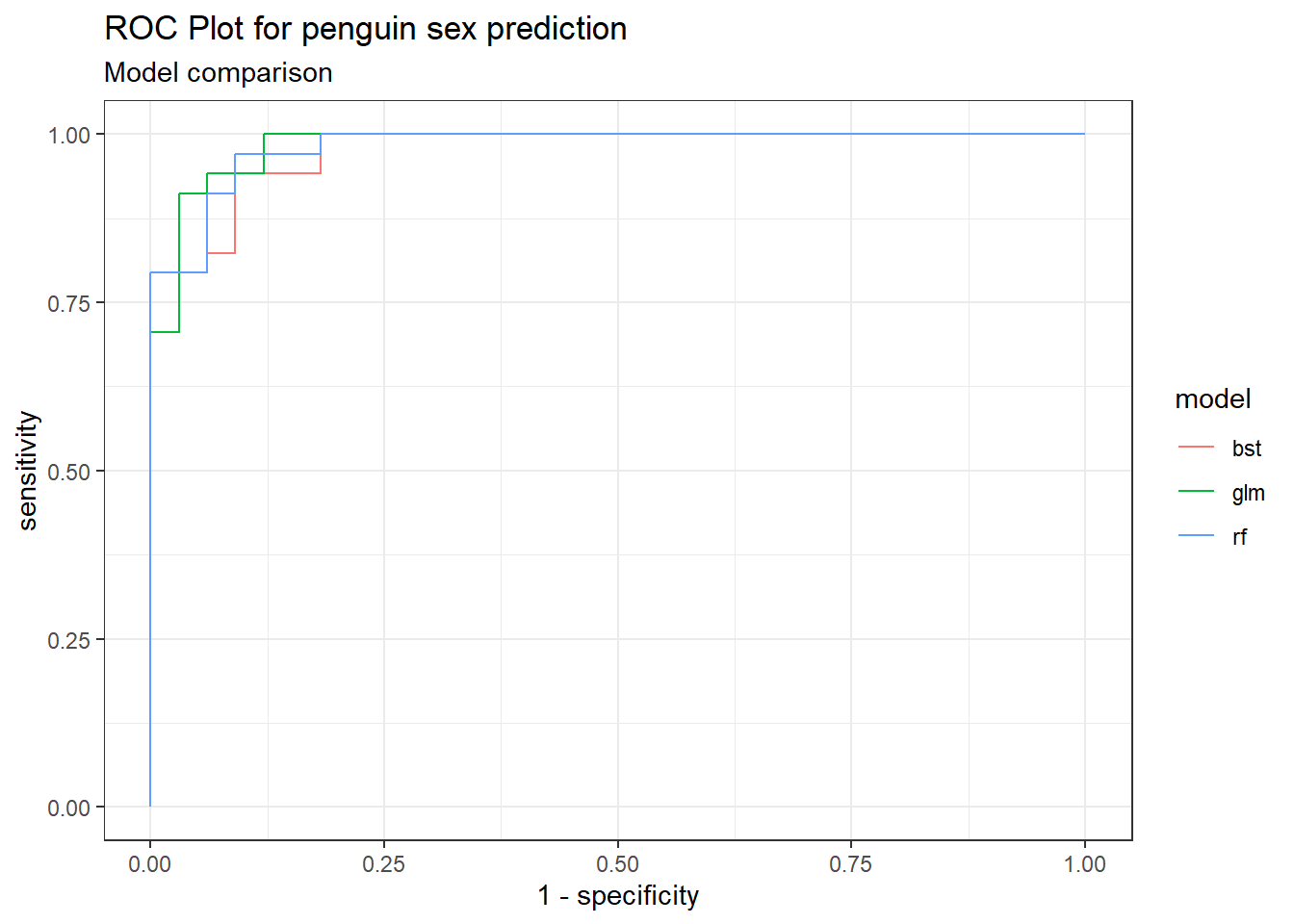
כפי שניתן להתרשם מהתרשים, לשלושת המודלים ביצועים טובים יחסית.
roc_plot_comparison_data <- penguin_test %>%mutate(rf_prob = penguin_pred_prob$.pred_male) %>%mutate(glm_prob =predict(penguin_logistic_fit, new_data = penguin_test, type ="prob")$.pred_male) %>%mutate(bst_prob =predict(penguin_boost_fit, new_data = penguin_test, type ="prob")$.pred_male)# Create a tibble with a data column containing the tibbles, then run roc_curveroc_data_all <- roc_plot_comparison_data %>%pivot_longer(cols =-c(species:year)) %>%group_by(name) %>%nest() %>%mutate(roc_plot_data =map(data, ~{roc_curve(.x, value, truth = sex, event_level ="second") } )) %>%unnest(roc_plot_data) %>%mutate(model = stringr::str_remove(name, "_prob")) %>%mutate(`1 - specificity`=1- specificity) %>%arrange(`1 - specificity`, sensitivity) %>%distinct(name, `1 - specificity`, sensitivity, .keep_all = T)roc_data_all %>%ggplot(aes(x =`1 - specificity`, y = sensitivity, color = model)) +geom_step() +ggtitle("ROC Plot for penguin sex prediction", subtitle ="Model comparison")
בפרק התמקדנו במודלים מונחים (Supervised learning), באמצעות חבילת tidymodels. ראינו את השלבים המרכזיים בבניית מודל סטטיסטי. התחלנו בהבנת המושג מודלים מונחים, ופירטנו את תהליך העבודה הכולל חלוקת הנתונים לקבוצת אימון, ולידציה, ומבחן, בניית מתכון להכנת הדאטה, הגדרת המודל, כיוונון המודל, הערכת ביצועי המודל, ושימוש במודל לחיזוי תצפיות חדשות.
8.11 קריאה נוספת
לצורך קריאה והעמקה נוספת בתהליך המידול, מומלץ לקרוא את (Kuhn and Silge 2022) המפרט על השימוש בחבילת tidymodels עם דוגמאות רבות. הספר זמין באינטרנט.
המדריך העברי למשתמש ב-R נכתב על ידי עדי שריד בהוצאת מכון שריד
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning. Springer US. https://doi.org/10.1007/978-1-0716-1418-1.
Kuhn, Max, and Julia Silge. 2022. Tidy Modeling with r. " O’Reilly Media, Inc.".